BeautifulSoupでWeb情報収集(スクレイピング)
前書き
去年の5月頃、対応する業界の会社の状況を調べることがありました。その際、参考になりそうなサイトを見つけたのは良かったものの、サイトに記載されている情報の数が非常に多く、データを収集するのに非常に苦労しそうなことがありました。
その際、PythonとBeautifulSoupを使うことで、同じような形式で表示されているページの情報を一括にまとめるスクリプトを作って、作業を省力化したことがありましたので、その時のスクリプトを紹介します。(スクリプト自体は、対象のサイトに大分適応させているので、汎用的な部分は少ないかもしれません。)
htmlの取得
まずは、指定したURLからのhtmlの取得部分です。指定したURLと共通部分のパスに加え、末尾に1~110までを結合する形でURLを作成、urllibのgetでhtmlを取得してローカルにファイルとして作成しています。今回情報を取得したかったサイトのルールとして、共通のURL+連番となっていたことからこんな感じのルールでデータを取得するようにしていました。
正直、ローカルにわざわざ、htmlファイルを作成するのは必須ではないのですが、こっちの方が後々調査するときに楽だと思ったので、一旦にローカルに落とす形にしています。
ファイル名:get_html.py
import traceback
import json
import urllib.request
import urllib.error
base_url = 'https://xxxx.xxx/' #宛先のベースURL
list_base = 'xxxx' #URLの共通部分
base_path = "C:\\Users\\public\\data\\"
def main():
print(base_path)
for i in range(1,110):
url = []
url.append(base_url)
get_name = []
get_name.append(list_base)
get_name.append(str(i).zfill(3) + '.html')
out_file = []
out_file.append(base_path)
url.extend(get_name)
out_file.extend(get_name)
#print(''.join(url))
try:
req = urllib.request.Request(''.join(url))
with urllib.request.urlopen(req) as res:
out_data = res.read().decode("utf-8")
with open(''.join(out_file),mode = 'w',encoding = 'utf-8') as fs:
fs.write(out_data)
except urllib.error.HTTPError:
pass
except:
print(traceback.format_exc())
if __name__ == '__main__':
try:
main()
except:
print(traceback.format_exc())
finally:
pass
Beautiful Soupによる解析
htmlの取得が完了したので、次はBeatiful Soupを使って、htmlから取得したい情報を抜出します。今回、htmlにはtitleに社名と、下のようなtableが記載されており、その情報を取得しようとしていました。
| 設立年月日 | 1991年10月3日 |
|---|---|
| 住所 | 東京都XXXXXX |
| 資本金 | ¥999,999 |
| 年商 | ¥999,999 |
| 営業利益 | ¥999,999 |
| 経常利益 | ¥999,999 |
そこで、htmlパーサーであるBeautifulSoupを使い、下記のようなソースを作りました。内容としては、ダウンロードしたhtmlをループで読み込んでいき、読み込んだhtmlからbsObj.findAll("table")[0]でテーブルの情報を取得、テーブルのtr要素から、td要素を取得して、all_data.csvという一つのCSVファイルにまとめていきました。
ファイル名:parse_html.py
# -*- coding: utf-8 -*-
import csv
import os
import traceback
from bs4 import BeautifulSoup
base_path = "C:\\Users\\data\\"
list = os.listdir(base_path)
def append_data(file_nm):
csvRow = []
with open (base_path + file_nm , mode='r', encoding='utf-8') as rf:
html = rf.readlines()
bsObj = BeautifulSoup(''.join(html), "html.parser")
title = bsObj.findAll("title")[0]
table = bsObj.findAll("table")[0]
rows = table.findAll("tr")
csvRow.append(title.get_text().split('/')[1])
with open("all_data.csv", "a", encoding='utf-8') as file:
writer = csv.writer(file)
for i, row in enumerate(rows):
cell_title = row.findAll('th')[0]
cell_data = row.findAll('td')[0]
if i in [0,1,2,3,4,5,6,7]:
csvRow.append(cell_data.get_text().replace('\n',''))
writer.writerow(csvRow)
if __name__ == '__main__':
for file in list:
try:
append_data(file)
except:
print(file)
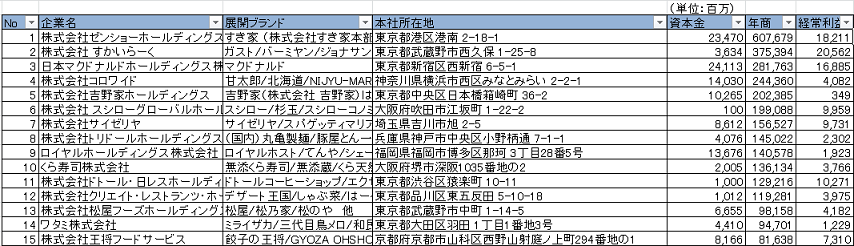
一通り処理が成功すると、下のようなイメージで、1ページごとに記載されていた情報を一つのCSVファイルにまとめることができました。
後書き
Webからの情報収集の簡略化ということで、今回はPythonの標準機能とBeautifulSoupを使って、htmlの収集とパース処理を実施しました。サイトによっては、クロールを禁止しているところもあるので注意は必要ですが、Webの情報を効率よく収集するには、今回のようにプログラム化してしまった方が楽になると思います。
今回はhtmlの収集にPythonの標準機能で実施しましたが、Scrapyだったり、Seleniumの方が高機能で色々できるので、いずれそちらも紹介できたらなーと思います。(実際、Scrapyでいくつかプログラムを組みましたが、DB連携部分やURLの走査には、そちらの方が大分楽にできます。)